Discover new targets, faster
Discover new targets, faster with Natural Language Processing
Natural Language Solutions for drug discovery and target ID
We have been working in the drug discovery space for over 20 years, honing our technology and supporting search strategies for pharma companies who are trying to understand gene-disease associations, pathways, and discover biomarkers.
Keeping abreast of all the relevant literature you need to identify targets and understand the association of genes and diseases is an almost impossible task. Key information can be missed. We can provide easy access to many content sources to stay informed on the latest developments published in public sources and through subscriptions, including ClinicalTrials.gov, patents, Medline, CCC (Copyright Clearance Center), and many more! Our broad range of ontologies allows you to normalize information across these data sets and bring in your own data to see the complete landscape.
Our validated NLP blends rules, ontologies, transformers, and large language models for optimal results, producing higher F-scores (output quality) than each method individually. The technology allows researchers to identify targets in disease areas of interest and establish ranking based on factors such as safety and potential for therapeutic benefit. Related areas such as biomarker discovery and genotype-phenotype associations can also benefit.
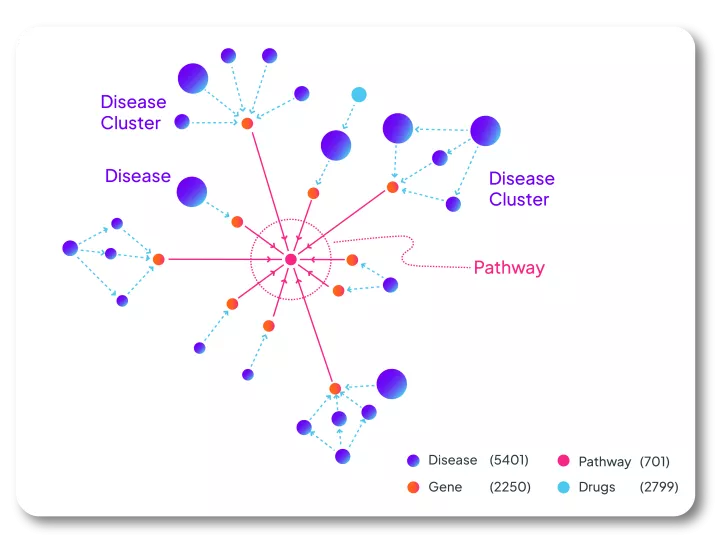
Integrated text mining for rare disease knowledge graphs
A top 10 pharma used Linguamatics NLP to evaluate indication expansion potential by creating a knowledge graph to see potential links between rare diseases and their portfolio. They used our NLP across many data source to extract various relationships and information including, but not limited to, rare disease-protein interactions, drug-protein interactions, phenotype-genotype relationships, incorporated cell type and pathway information, etc. The output was visualized in a knowledge graph to visualize the links and the directionality. Using this NLP text mining approach, they were able to quickly identify new indication opportunities from target-disease pairs that have various commonalities based on broad scientific medical and strategic values.
Target prioritization at Pfizer
This case study describes how Linguamatics NLP platform has been used to capture valuable information from the Life Science literature, saving time and increasing productivity.
Target selection at AstraZeneca
AstraZeneca’s aim was to integrate text mining with other discovery capabilities so that the value of literature information could be exploited more widely. Using Linguamatics NLP platform the team developed an agile and scalable enterprise text mining capability to improve productivity and to develop an objective, holistic view of target options and improve quality in early discovery decision-making.