Technology & digital
Scale your tech and digital initiatives across any language
Localization solutions for healthcare and life-science technology and digital professionals
Equip your tech stacks and teams with the best industry-specialized solutions for localization and reach your audiences globally fast, simply and cost efficiently.
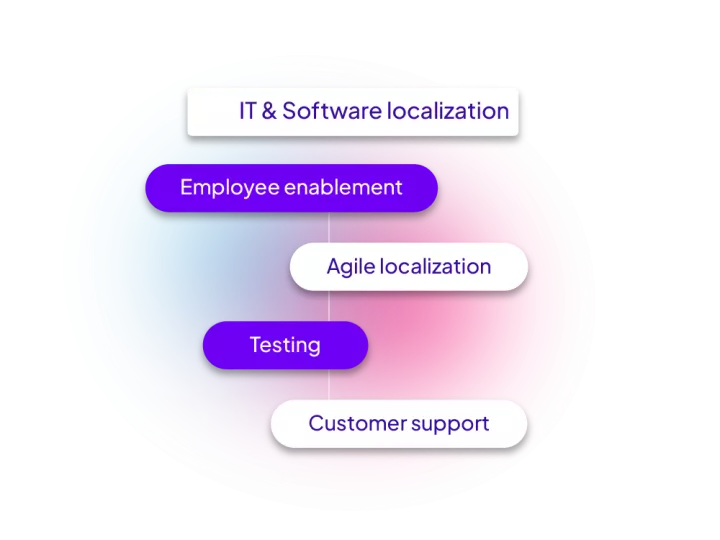
Employees and development teams get access to all relevant language solutions in a few clicks, always safe and compliant with your data security guidelines, while saving time and money.
Linguamatics technology allows your organization to benefit from massive efficiencies, while providing all employees with reliable and compliant language solutions at their fingertips.
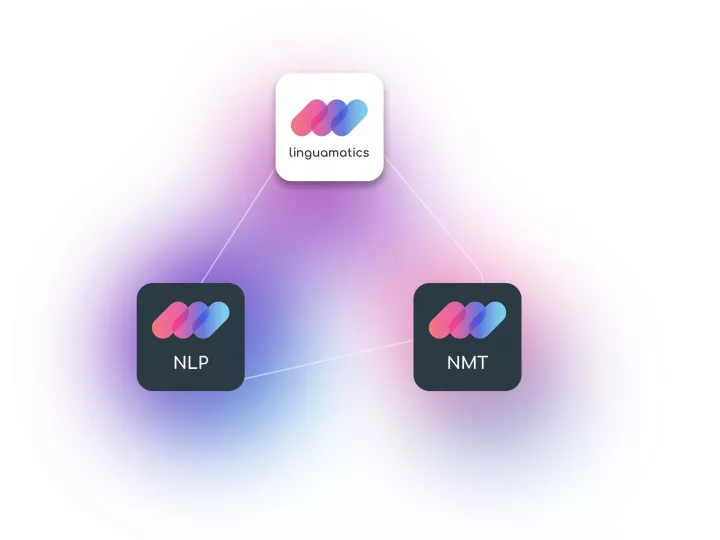
Linguamatics hub is our translation management system designed for our industry’s unique needs in terms of compliance, speed and integration capabilities. It enables any team that requires language solutions to obtain them in a few clicks.
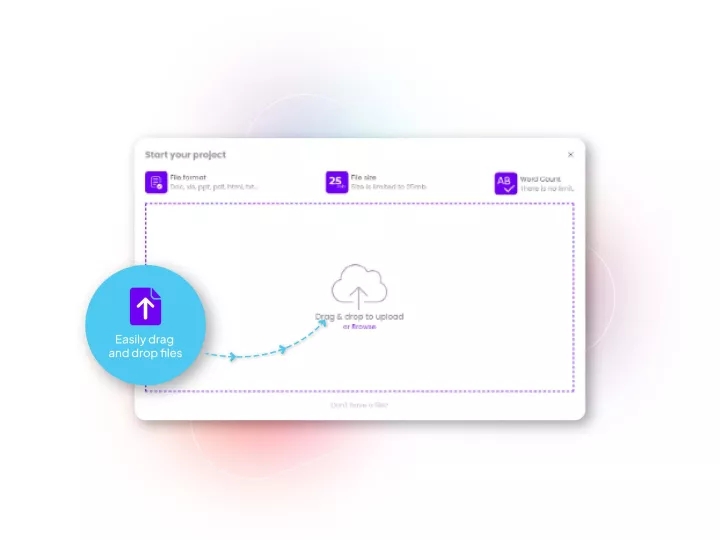
Linguamatics translate is a secured and compliant instant translation system that can be leveraged for some unique use cases of technology enablement:
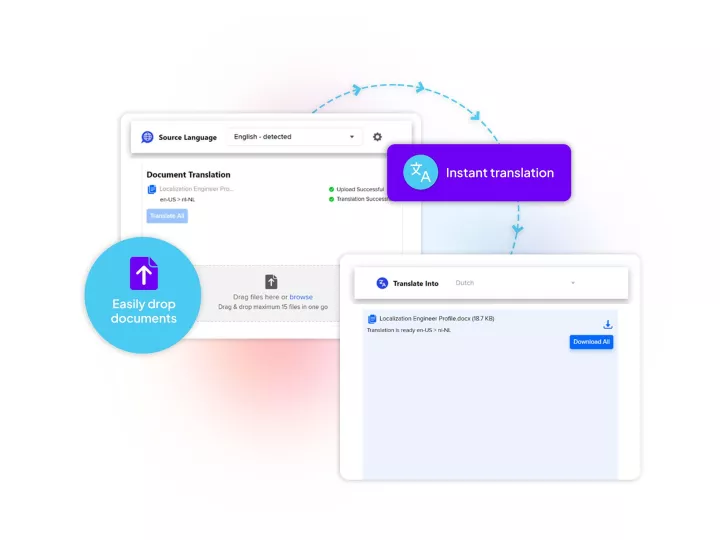
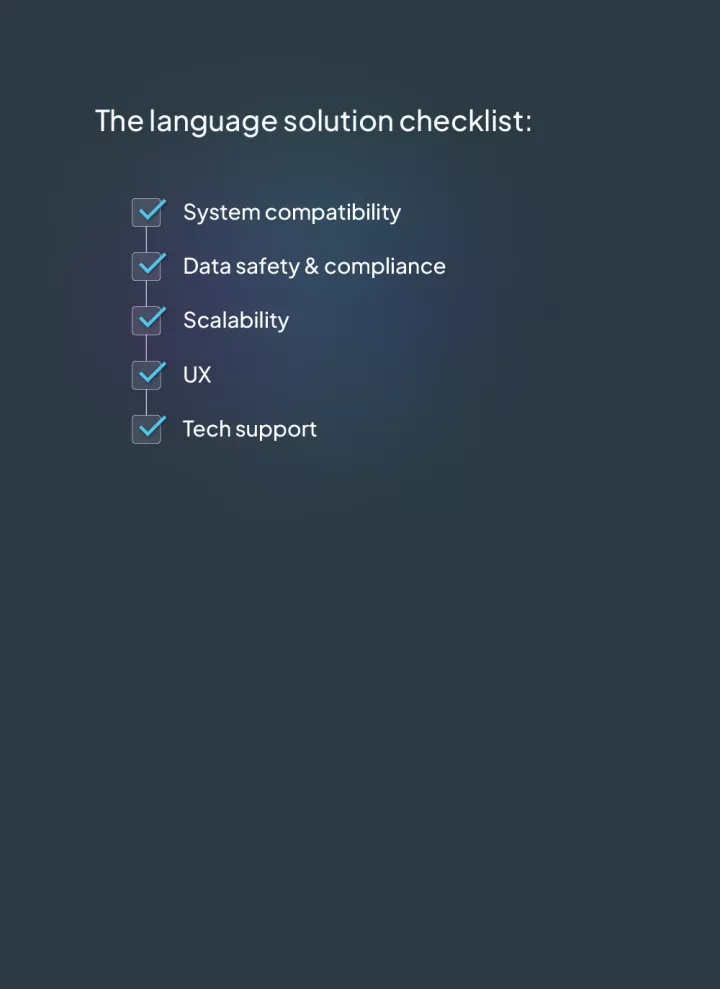
By strategizing their selection process, IT teams can implement effective translation solutions that enhance efficiency, streamline processes, and drive organizational success and efficiencies.